
Exploring embeddings for categorizing content at scale
Organizing and finding information efficiently is at the heart of any robust content management system. Though content is typically classified as structured or unstructured, the difference between structured and unstructured information is a matter of degree - it is a spectrum. To derive structure from the different content repositories within an organization, we need to apply a variety of techniques to derive meaningful labels, topics, summaries, and entities (names, addresses, etc.) from the raw content. All of these tasks can be discussed under the general topic of natural language processing (NLP). For labels or categories, this structure can range from generic categories such as fiction/non-fiction to specific categories such as individual IRS or LIBOR document types. Here we will explore using embeddings (a mathematical representation of a sequence of text) to perform these categorizations.Recently there has been a plethora of stories around advancements in machine learning and NLP in particular. Today’s advancements in NLP mirror similar advancements in computer vision that have been a major area of research for a while. For software engineers, the natural question is how to translate these into solving real business problems. While here we focus on exploring NLP techniques, it is important to keep in mind that an ML model is typically only one part of the entire process. We usually spend more time gathering clean data, pre-processing, post-processing, maintenance and scaling tasks to deliver an effective solution. Historically, a variety of supervised and unsupervised techniques have been applied to the problem of deriving structure from unstructured content, such as
- Expectation maximization (EM),
- Naive Bayes classifier,
- Latent semantic analysis,
- Support vector machines (SVM),
- K-nearest neighbor algorithms,
- Decision trees, and
- Deep learning.
A variety of statistical methods have been applied since the '50s to infer meaning from unstructured data. Over time this has given us mechanisms such as latent semantic analysis to surface higher-level concepts from documents to topics by using conditional probabilities and co-occurrence matrices. Though manipulating these matrices for large vocabularies is both compute and memory intensive, these methods yield good results for reasonably sized sets of documents such as the task of topic modeling.
Deep learning
Deep learning models are now of particular interest for developing models that can self-supervise, i.e., that can use the raw content (corpus) itself to guide their own learning. This is important as the availability of clean, labeled data is a chronic problem for organizations. With the recent spate of privacy-related compliances, collecting data training models has become even more difficult. But, through self-supervision, it is now possible to leverage the entire content available on the internet for training. There has been a steady march of transformer-based architectures reaching better accuracy on language modeling tasks by ingesting larger and larger input datasets. For example, GPT-3 was trained on more than 45TB of compressed plaintext gathered from the internet, not including other sources. A consequence of this march to larger architectures is that only the largest companies can perform this task due to the huge amounts of computing resources required.
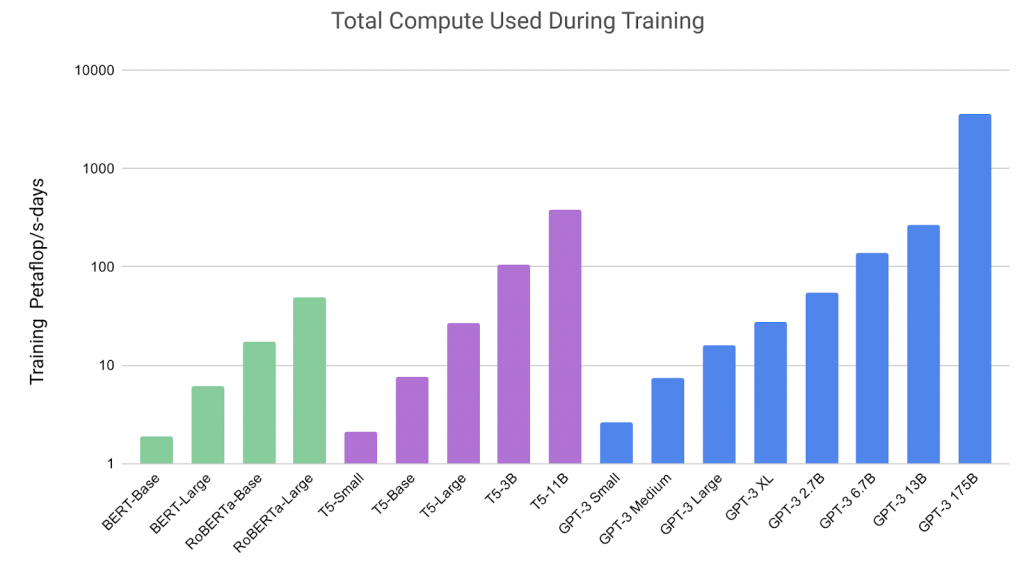
Compute requirements of recent models (from [2005.14165] Language Models are Few-Shot Learners)It is interesting to note that these models are trained on specific tasks such as predicting the next word in a sentence or predicting words that are hidden from the model in the input. But, these tasks force the model to learn the structure of the language, such as rules of good grammar and allows it to capture the variety of contexts in which words are used (aka a language model). Originally these models were targeted to solve language translation and question-answer problems. But by re-architecting the original design, we can apply models such as BERT to more focused (and probably more useful) tasks for categorizing documents, identifying named-entities, and generating context-sensitive embeddings for text sequences. Embeddings in particular can be then fed into other more specialized models. This can be done by stripping away the task-specific layers from the model and adding additional layers for fine-tuned tasks. Therefore as long as the weights of a pre-trained model are publicly made available, anyone with access to a reasonable amount of computing can experiment and use these massive models for their own specific purposes with orders of magnitude less data. Though OpenAI has withheld opening up GPT-3, fortunately, details of many of these models have been shared.
Similarity
To leverage these models for the task of categorizing content, we need to first explore the concept of similarity. This concept is central to solving a variety of problems in NLP, whether at the character sequence, word, or document levels. The syntactic similarity of words has been tackled in the past by reducing different forms of a word to its base form through stemming and lemmatization. Stemming typically uses heuristics to remove common inflections, while lemmatization goes further to include the morphological analysis of words to derive the dictionary form of a word (i.e., lemma). These techniques are used extensively within search engines to broaden the set of hits for a given query. We could consider extending this mechanism to include synonyms of a word either manually or using a taxonomy such as WordNet. This is supported by mainstream search engine frameworks such as the Synonym token filter. This is now getting us into the territory of semantic similarity. But note that a project such as WordNet requires decades of painstaking work and is thus not available for all languages and also cannot cover complete vocabularies. Here, we can leverage deep learning models to automatically derive these semantic relationships that allow us to perform higher-level similarity tasks, which leads us to the subject of embeddings. Translating simple word-level embeddings to context capturing embeddings is one of the key building blocks for a model such as BERT.
Embeddings
As deep learning models deal exclusively with numerical data, we need a way to represent symbolic sequences such as words as numbers. Embeddings give us that representation and are the mathematical representation of a sequence of text ( Word embedding, sentence, paragraph, or document). We are effectively mapping a vocabulary to a set of vectors that can be then fed into more specialized networks or manipulated via a set of mathematical operators. One of the important results of past language modeling work is the observation that linguistic items with similar distributions have similar meanings. A natural (and innovative) extension of this hypothesis has been used in transformer models to derive word representations that capture the use of a specific word in the context of other words within a given corpus.
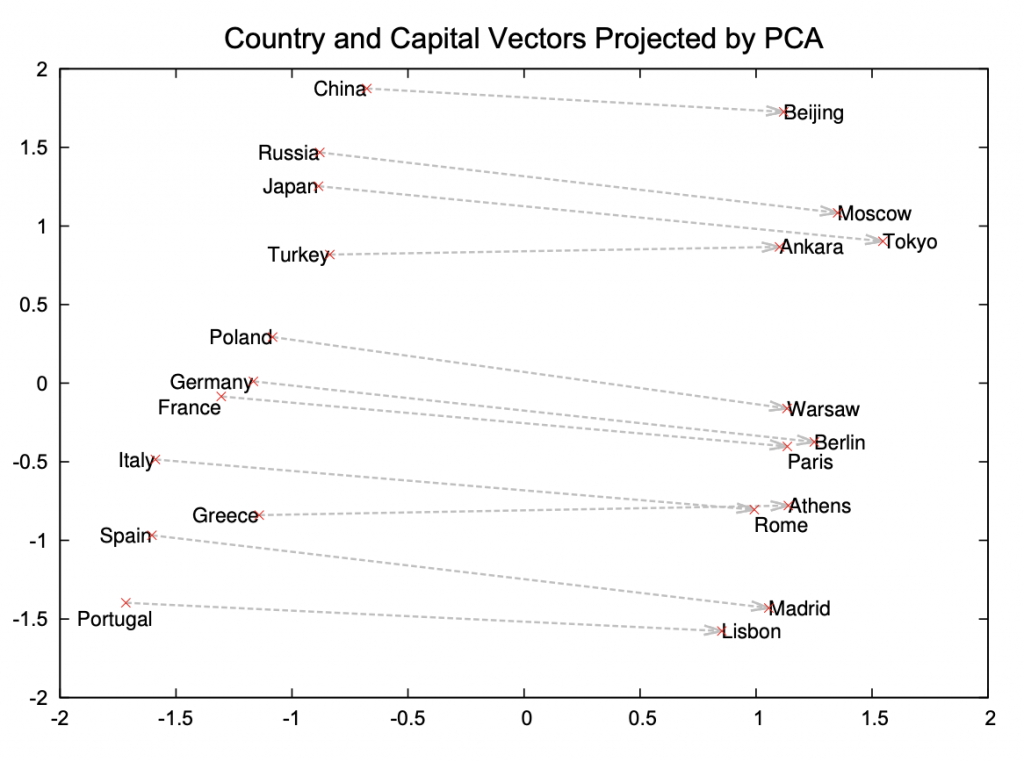
Illustration of word similarity (from Distributed Representations of Words and Phrases and their Compositionality)We can directly use embeddings to expand keywords in queries by adding synonyms and performing semantic searches over sentences and documents through specialized frameworks. But as mentioned before, we can also use these indirectly as inputs into more focused models for information retrieval tasks such as finding parts of speech and tagging names, sentiment analysis, and general classification tasks. This is necessary as these downstream models also operate on numerical inputs and not symbolic representations.It is interesting to note that the transformer-generated embeddings are a natural evolution of earlier work on word embeddings. Word2Vec, a set of seminal algorithms, empirically demonstrated the generation of word representations that captured some representation of the context in which they appeared. Amazingly this was achieved through a small set of operations to incrementally pull words that co-occur within a small window in the corpus closer together and pushing (a sample) of other words apart. This technique (and additional heuristics) allowed the authors to scale the mechanism to large-scale datasets, which was a challenge with the earlier probabilistic methods. Rapid improvements followed with GloVe: Global Vectors for Word Representation and Enriching Word Vectors with Subword Information (FastText). The latter method also addressed the issue with dealing with unknown (or out-of-vocabulary words) present among earlier approaches. In many cases, as long as we understand the limitations of these earlier embeddings, it may still be simpler to build systems based on these rather than more sophisticated representations such as transformer networks. As a side note, embeddings can be used to capture more than sequences of text. Methods such as Word2Vec can be applied to the task of capturing user interactions with an application and reveal the deeper semantic similarity between users.
Embeddings in action
One way to see embeddings in action is to exercise the masked language model task that a transformer like BERT is trained on. We can mask out a word and see what would be some possible suggestions based on the perceived context of the sentence. Let’s feed BERT will some sample fill-in-the-blanks (denoted in the following by [MASK]) as,from transformers import pipeline, BertTokenizer, BertForMaskedLM
Which gives us an output like this:
We can see that (a) the first sentence is tilting more towards narcotics (b) the second one more towards medicine, and (c) BERT does not know what Covid is, and it tries to use its fallback mechanism (to use sub-words) for unknown words. We can check its vocabulary for specific words as
Which indicates that “cocaine” is in the vocabulary while the other words are missing. If such words occur frequently in our target datasets, then we should consider extending the vocabulary to include these words by either (a) getting models pre-trained on a specific domain such as biomedicine, or (b) adding new words and training BERT to generate new embeddings for those words.
Conclusion
So what are some important takeaways from this analysis?
- If using static embeddings (such as Word2Vec), we need to explicitly handle out-of-vocabulary words which can be ignored or a zero or random vector would need to be used.
- Fine-tuning pre-trained models requires careful analysis of expected content to handle important words that are missing from the model.
- If not careful, fine-tuning can result in over-fitted models that will not generalize well. BERT authors have published certain heuristics for this procedure in A.3 Fine-tuning Procedure.
- If sufficient clean data is available, we could consider training a transformer from scratch, though that may eat up weeks of expensive compute resources and still not be sufficiently better than public pre-trained models. There are a few examples of these efforts, such as this one from one of our data scientists.
- Over time it is easy to get into gnarly issues with comparing incompatible embeddings as new versions are developed and deployed. The lineage of embeddings, therefore, needs to be handled carefully in production.
With these caveats, it is now very feasible to achieve state-of-the-art results on specialized datasets and applications if we bring a deep understanding of specific business domains to the problem of content management.





